

Tokens de diseño para distribuir decisiones
Qué son los design tokens, cómo se generan y cómo podemos transformarlos en código que entienda un navegador


Como prometí el año pasado, empezamos 2024 con temas novedosos.
Hoy hablamos de design tokens, un tema al que últimamente le he prestado bastante atención por las implicaciones que tiene tanto en el desarrollo frontend como en el diseño.
Al final el software es algo que está vivo y tiende a cambiar constantemente. El hacer que esos cambios se distribuyan entre todas las aplicaciones puede ser una tarea titánica, sobre todo si el software está lastrado por mucho legacy.
Introducción
Hasta hace relativamente poco las decisiones a implementar que se tomaban en diseño no estaban discretizadas. Es decir, diseño suele hablar un lenguaje diferente al que solemos emplear en desarrollo, inclusive cuando estamos construyendo la misma aplicación.
Por eso habitualmente los desarrolladores deben traducir para llevar decisiones en lenguaje natural a la implementación, o lo que es lo mismo, al lenguaje que el desarrollador utiliza en ese momento.
Por ejemplo, para un desarrollador frontend que programe bajo el stack HTML5, la traducción de “la cabecera es de color verde” supondrá extraer la información técnica relativa a la decisión y posteriormente generar el código CSS acorde:
header {
background-color: green;
}
En cambio, para un desarrollador de aplicaciones móviles, la traducción de esa decisión de diseño a código será drásticamente distinta.
Esto no solo provoca que se pueda perder información relevante tratando de traducir decisiones más complejas, sino que pagamos un coste elevado en cuanto a la velocidad de implementación.
Si bien es cierto, que todavía necesitamos del lenguaje natural para entendernos los unos a los otros, una vez que las decisiones estén tomadas debería de existir un lenguaje oblicuo que entiendan los humanos (diseñadores, desarrolladores), los programas (ya sean escritos en Javascript, CSS3, Kotlin, Java o Swift) y las maquinas (ChatGPT, cualquier modelo grande de lenguaje o LLM).
Para ello existe el concepto de design tokens.
¿Qué son los tokens de diseño?
La palabra token se ha visto usada de forma exponencial en los últimos años en el ámbito de las criptomonedas por su fuerte relación con los conceptos criptográficos en los que se basan. Sin embargo, la mínima expresión de un token es la representación de un valor.
Así como las variables de javascript son nombres que enlazan valores, los tokens son símbolos que pueden enlazar cualquier tipo de valor.
El significado de ese conjunto token/valor dependerá del contexto donde los utilicemos.
¿Os acordáis cuando ibais a la feria a montaros en los “cacharritos” (es como llamamos a las atracciones en el lugar donde crecí) y cuando comprabais las entradas os daban una ficha? Esa ficha es nuestro token y en este contexto el valor que representan es un viaje en los coches de choque.
Con este escenario en mente podemos decir que un token es:
Una unidad de valor emitida por una entidad que representa una propiedad
La entidad en la feria son los feriantes que te expiden una ficha que representa un viaje en una atracción. Intercambiamos estas fichas por viajes en atracciones. Podría decirse que tenemos la propiedad de un viaje en un momento determinado.
En el contexto de los sistemas de diseño, el equipo o miembros del sistema expiden fichas (o tokens) que representan decisiones dentro del sistema.
Un token es la mínima expresión de una decisión de diseño.
Igual que una ficha verde equivale a un viaje en el túnel del terror, el token color_background_button_error equivale a la decisión de poner de color #E57373 un botón en el estado error.
La equivalencia o el cambio lo establece la entidad emisora. Así como la feriante puede decir mañana que las fichas verdes ya no equivalen a viajes sino a un algodón de azúcar, los propietarios del sistema de diseño pueden tomar la decisión de cambiar el color a una tonalidad más rojiza, sin que ello afecte al token.
Otra forma de entender los tokens es pensar en ellos como identificadores sobre valores. En lugar de usar el valor directamente, usamos un ID y nos volvemos agnósticos a cambios en los valores.
Valores o tokens
Imagina que tenemos una aplicación relativamente grande implementada bajo un stack web con HTML5, donde cada decisión de diseño está directamente implementada en el lenguaje (CSS en nuestro caso).
Y ahora imagina si nos piden desde diseño implementar algo tan inocente como el modo oscuro. Si en lugar de tokens, tenemos los valores desperdigados por todo el código fuente, estaremos en un aprieto importante para poder implementar el nuevo tema.
La tragedia se masca, además, cuando no solo tenemos una aplicación web, sino que contamos con aplicaciones móviles y de escritorio y cada una habla un lenguaje distinto.
Muchos estaréis diciendo que lo lógico y la buena práctica es no usar el valor directamente, sino utilizar constantes o variables. Y si, normalmente, una aplicación tendrá sus variables definidas con los valores.
La realidad, sin embargo, es un poco más complicada. Normalmente es fácil discretear los valores fundacionales (colores, tamaños, etc.), pero no se suelen fragmentar valores más complejos (como el margen de un botón) y lo que es peor, la nomenclatura suele ser una decisión unilateral de desarrollo que significa poco o nada para un diseñador.
Por lo general si no existe un sistema de diseño habrá muchas decisiones que se tomen ad hoc para el proyecto en cuestión y no se tengan representadas como variables.
Imagina que la paleta de colores se implementa con constantes y que además los nombres se definen en conjunción con diseño. Se podría pensar que el adoptar un tema oscuro sería sencillo, pero ¿qué ocurre con las imágenes o los iconos? es posible que muchas de ellas en un tema oscuro no tengan sentido por generar un contraste demasiado alto y es más probable aún que esas decisiones no estén centralizadas.
Centralizando decisiones
Lo que buscamos es recoger todas las decisiones en un único lugar o lo que es lo mismo, tener una fuente de verdad con todas las decisiones de un sistema de diseño.
Además, queremos que esa fuente de verdad sea agnóstica al equipo, al proyecto y a la tecnología y que pueda ser fácilmente mantenida y actualizada.
Para ello tenemos que buscar un lenguaje que nos permita representar toda la información de manera precisa, que sea fácilmente almacenable, que permita hacer búsquedas y aplicar transformaciones, y que sea entendible tanto por maquinas como por humanos.
En ingeniería del software cuando queremos comunicar e intercambiar datos entre dos entes (humanos y máquinas, o máquinas y otras máquinas) recurrimos a lo que se denomina “Formatos de intercambio de datos”.
Hay muchos formatos de intercambio, pero el más conocido y que seguramente te sonará es JSON.
JSON es el acrónimo de Javascript Object Notation y puede ser fácilmente generado y entendido por humanos y parseado por programas, y es que formato que utilizaremos para definir nuestra fuente de la verdad.
Definiendo la fuente de la verdad en JSON

Basta decir que para poder recopilar todas las decisiones de diseño en un fichero JSON, primero han de ser tomadas y consensuadas idealmente por los miembros del sistema de diseño. Nosotros partiremos de la base de que las decisiones ya están tomadas y trabajaremos a partir de ahí.
El equipo puede proporcionarnos la información de múltiples formas, desde lenguaje natural a los ficheros JSON directamente generados desde herramientas como Figma.
Antes de empezar a generar ficheros, necesitamos definir la arquitectura que posteriormente implicará la nomenclatura que vamos a seguir. Normalmente los tokens se organizan de forma jerarquía en una estructura de árbol. La copa de ese árbol es la Categoría la que pertenece el token y de ella cuelgan el tipo de decisión y de esta el elemento sobre el cual se aplican.
Por ejemplo, podríamos tener una categoría Color, del que cuelgan tipos como Background o Border y que aplican sobre Button o Paragraph.

Esta estructura se define como CTI (Category/Type/Item) y suele ser la forma recomendada para poder aplicar transformaciones o hacer búsquedas más fácilmente.
Podemos granular esta jerarquía o modificarla lo que queramos colgando nuevas ramas para representar información adicional del Item (como podría ser el tipo) o incluso el estado, pero es importante tener como mínimo estas tres grandes categorías.
Con todo esto en mente y después de hablar con el equipo del sistema de diseño, acabamos con tres ficheros así:
color/base.json
{
"color": {
"base": {
"primary": { value: "#007bff" },
"secondary": { value: "#00ff00" }
}
}
}color/button.json
{
"color": {
"background": {
"button": {
"primary": { value: "#007bff" },
"secondary": { value: "#00ff00" }
}
},
"text": {
"primary": { value: "#ffffff" },
"secondary": { value: "#333333" }
}
}
}
size/font.json
{
"size": {
"font": {
"base": { value: "16px" },
"medium": { value: "18px" },
"large": { value: "24px" }
}
}
}
Estos ficheros pueden ser creados a mano o mediante alguna herramienta como Figma. En este caso nosotros hemos obtenido lo que nos dan los plugins para tokens de diseño.
Procesando la fuente de la verdad
La estructura dividida por ficheros es útil para poder consultarla y guardarla, pero de cara a poder aplicar transformaciones o resolver referencias necesitamos generar un único fichero con todo el árbol.
Para ello voy a crear una función en Javascript que dada una lista de objetos, los fusione todos de forma profunda en un único objeto:
import * as R from 'ramda';
function mergeObjects(objects) {
return objects.reduce((result, object) => {
return R.mergeDeepLeft(result, object));
});
}Estoy usando la utilidad mergeDeepLeft que me ofrece ramda para simplificar el código.
Si te asusta el reduce que hay ahí y quieres aprender a entenderlo, te recomiendo que leas este artículo. Si por el contrario no estas interesado, te dejo a continuación la versión iterativa para que puedas seguir leyendo :)
import * as R from 'ramda';
function mergeObjects(objects) {
let result = {};
objects.forEach(object => {
result = R.mergeDeepLeft(result, object);
});
return result;
}Y finalmente podemos utilizar para importar y fusionar todos nuestros ficheros de tokens para generar el árbol definitivo:
import baseColor from './color/base.json';
import buttonColor from './color/button.json';
import sizeFont from './size/font.json';
const tree = mergeObjects([baseColor, buttonColor, sizeFont]);Y como resultado:
{
"color": {
"base": {
"primary": {
"value": "#007bff"
},
"secondary": {
"value": "#00ff00"
}
},
"background": {
"button": {
"primary": {
"value": "#007bff"
},
"secondary": {
"value": "#00ff00"
}
}
},
"text": {
"primary": {
"value": "#ffffff"
},
"secondary": {
"value": "#333333"
}
}
},
"size": {
"font": {
"base": {
"value": "16px"
},
"medium": {
"value": "18px"
},
"large": {
"value": "24px"
}
}
}
}Ahora que tenemos un árbol que representa a cada una de las decisiones de diseño, podemos transformarlo en lo que queramos ya que al estar en formato JSON es agnóstico de la tecnología que estemos utilizando.
Transformando el árbol de forma recursiva

Ahora que ya tenemos nuestro árbol podemos empezar a construir interpretes para transformalo en lo que queramos.
Por ejemplo,si desarrollamos para web nos gustaría tener todas las decisiones de diseño en forma de variables de diseño que se consumen directamente por las aplicaciones. Para ello como ya contamos con una fuente de verdad, simplemente tenemos que transformarla para que partiendo del árbol definido arriba acabemos con algo parecido a esto:
--color-base-primary: #007bff;
--color-base-secondary: #00ff00;
--color-background-button-primary: #007bff;
--color-background-button-secondary: #00ff00;
--color-text-primary: #ffffff;
--color-text-secondary: #333333;
--size-font-base: 16px;
--size-font-medium: 18px;
--size-font-large: 24px;Para poder pasar de tener nuestros tokens representados como una estructura arbolea, a tener una cadena de texto con los nombres de variables CSS y sus valores, necesitamos iterar la estructura y convertirla.
La forma más intuitiva de recorrer un árbol es mediante recursividad. Son de esos pocos problemas en los que la versión iterativa es mucho más compleja que la recursiva, ya que si os fijáis bien cada rama del árbol se puede entender en sí misma como otro árbol:

Así hasta encontrar un nodo hoja que no tenga hijos, terminal.
Si tenemos una función que recorre árboles a partir de una rama padre, cuando encontremos una hoja con hijos (es decir, otro padre) podremos volver a aplicar la función sobre esa hoja y así sucesivamente.
Así, el algoritmo que necesitamos tiene que hacer lo siguiente:
Dado un nodo padre:
Tenemos que iterar sobre todas sus hojas
Si el padre no tiene hojas hijas (caso trivial)
Devolvemos el padre
Si el padre tiene hojas hijas, ejecutamos de nuevo el punto 1 sobre esta hoja
Lo más sencillo cuando afrontamos un problema de recursividad es siempre identificar el caso trivial o, dicho de otro modo: el caso que no tiene recursividad.
En nuestro ejemplo, el caso trivial es tener u nodo que solo tenga una hoja llamada “value”. Es decir, estemos en los más profundo de una hoja con un objeto que contiene directamente el valor.

No importa la profundidad que tenga un árbol u hoja, siempre paramos cuando encontremos un objeto que tenga una propiedad value (de ahí la importancia de que todo el objeto deba tener una estructura común).
Generando variables CSS
Llegados a este punto, ya tenemos claro el cómo vamos a recorrer nuestra estructura de tokens para transformarla en lo que queramos, asique vamos a poner en práctica generando variables CSS a partir de nuestros tokens para que puedan ser consumidos por los equipos web.
Para poder hacer nuestro pequeño parser, tenemos que entender primero que pinta tiene una variable en CSS.
Las variables CSS se definen utilizando custom properties. Se escriben dos guiones y a continuación un nombre descriptivo y se le asigna un valor:
--my-variable: #ff;En nuestro caso, el nombre de la variable lo marca el camino del árbol que hayamos tomado hasta llegar al valor. Por ejemplo:
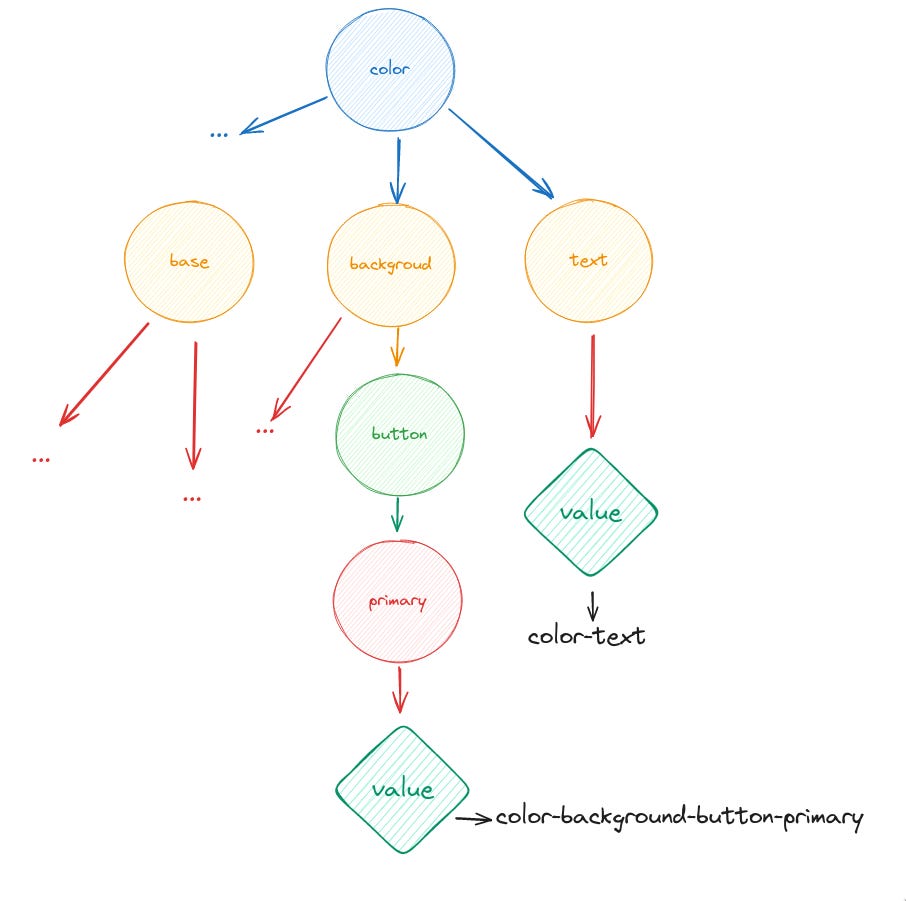
Si seguimos el camino del centro llegamos al token color-background-button-primary y si seguimos el de la derecha tenemos el token color-text, y así sucesivamente hasta terminar de recorrer el árbol.
El valor de cada variable la sabremos en el momento en el que lleguemos a un nodo terminal (caso trivial).
Vamos a empezar a programar. Cuando definimos una función recursiva solemos crear primero una función carcasa y dentro definir la función que será llamada recursivamente. Con esto ganamos la libertad de no exponer detalles de implementación con los parámetros de la función:
function generateCSSVariables(tokens) {
let cssVariables = '';
function recur(parent, prefix = '--') {
}
recur(tokens);
return cssVariables;
}La función generateCSSVariables toma un objeto tokens (que será nuestro árbol) y define dentro un variable para guardar las variables CSS (valga la redundancia), y la función recursiva.
El nombre de esta función puede ser cualquiera. A mí me gusta ponerle ‘recur’ para hacer explícito el hecho de que será una función que llamemos recursivamente, pero puedes optar por ponerle cualquier nombre, ya que es una función que no se va a exponer hacia fuera.
Esta función recursiva define dos parámetros: parent y prefix. El parent ya lo hemos explicado: corresponde a la cabeza del árbol o el sub-árbol. Seguidamente, el argumento prefix es el que vamos a utilizar para ir generando el nombre de la variable. Inicialmente y como hemos explicado arriba, empezamos con dos guiones.
Finalmente, invocamos la función pasando el primer padre (en nuestro caso el objeto tokens).
Vamos ahora a implementar el algoritmo que describimos antes para encontrar el caso trivial:
function recur(parent, prefix = '--') {
for (const [key, value] of Object.entries(parent)) {
if(value.value) {
cssVariables += `${prefix}${key}:${value.value};\n`
}
}
}Iteramos entre todos los hijos del padre (cada propiedad sería un hijo) y para detectar el caso trivial comprobamos si hay algún hijo que es un nodo terminal, es decir si su valor es un objeto con la propiedad value (por el eso el value.value!).
Tranquila si no lo ves. Te dejo un ejemplo:

Si el parent es “font”, este tiene un hijo “base” y el valor de este no tiene ninguna propiedad “value”, por lo que en este caso ‘font’ no sería terminal. En cambio, aquí:

Ahora el parent es “large” y su valor (el objeto) sí que tiene una propiedad “value”, por lo que en este caso “large” es terminal.
Sobre la línea:
cssVariables += `${prefix}${key}:${value.value};\n`Como es el caso trivial, directamente concatenamos la variable donde guardaremos todas las custom properties a un string formado por el prefix y la key actual. El valor lo sacamos de la propiedad value en el nodo terminal.
Y ahora nos queda los más fácil, llamar a función recursiva sobre un hijo que no sea terminal (que tenga más hijos dentro):
function recur(parent, prefix = '--') {
for (const [key, value] of Object.entries(parent)) {
if(value.value) {
cssVariables += `${prefix}${key}:${value.value};\n`
} else {
recur(value, `${prefix}${key}-`);
}
}
}Si estamos en un caso no trivial (es decir, tenemos un padre que tiene hijos), pasamos ese nuevo padre en el primer parámetro y generamos un prefijo nuevo compuesto de lo que había antes en el prefijo más la key del nuevo padre.
Parece un poco lioso porque lo es, pero lo mejor en estos casos es ejecutar el código y debugear para entenderlo :).
Si ahora ejecutamos la función, obtendremos:
--color-base-primary: #007bff;
--color-base-secondary: #00ff00;
--color-background-button-primary: #007bff;
--color-background-button-secondary: #00ff00;
--color-text-primary: #ffffff;
--color-text-secondary: #333333;
--size-font-base: 16px;
--size-font-medium: 18px;
--size-font-large: 24px;¡Y ya habremos transformado nuestro árbol de tokens representado en JSON a código que puede entender un navegador!
Seguidamente podemos escribir estos datos en un fichero y envolverlo en un bloque :root y podríamos servirlos a los equipos para su uso.
Conclusión
Si has venido a este artículo de nuevas sin saber lo que eran los tokens de diseño, espero que llegado este punto puedas decir lo contario.
Además del porqué de su existencia y el enfoque que se suele seguir a la hora de usarlos en desarrollo, te he dejado una implementación que permite transformar las decisiones de diseño a CSS. Imagina que, siguiendo este mismo proceso, generamos tokens no solo en tecnologías web sino en algo que pueda entender un desarrollador de Android o de IOS. Y si ya lo automatizamos de tal manera que cuando las decisiones se actualicen todo el mundo recibe un distribuible con variables, pues es una maravilla.
En próximos episodios investigaremos las transformaciones y las referencias. Si no quieres perderte nada, no olvides de suscribirte y si te ha gustado déjame un like :).
Nada más por hoy ;).