
Intruducción al patrón Flux
Porque Flux es superior a MVC en aplicaciones Frontend


Si no has pasado encerrado en una cueva los últimos 6 años, probablemente hayas oído hablar de Flux e incluso lo uses en tu día a día, ya sea a través de frameworks que han ido ganando popularidad como Redux o mediante implementaciones personalizadas en vanilla.
Sea como fuere, el patrón flux tiene mucho sentido en el mundo del front porque fue un patrón diseñado pensando en el mismo y no copiando patrones muy de back y de cómo hacíamos aplicaciones hace 10 años.
En el artículo de esta semana hablaremos, sorpresa, de Flux, de su aplicación a React y de porqué es superior a patrones como MVC.
Patrón MVC
Este patrón fue formulado por Trygve Reenskaug en 19791 y tenía el objetivo de separar la lógica de negocio de la lógica de presentación y aunque inicialmente fueron definidos varios “entes” encargados de controlar y asegurar está separación2, en la década de los 80 fue condensado a las 3 capas que hoy conocemos:
Modelo
Vista
Controlador
Y la idea de estas tres capas era simple. Por un lado, el modelo guarda la información de una aplicación, la vista es en teoría una representación de ese modelo y el controlador realiza la comunicación entre ambos:
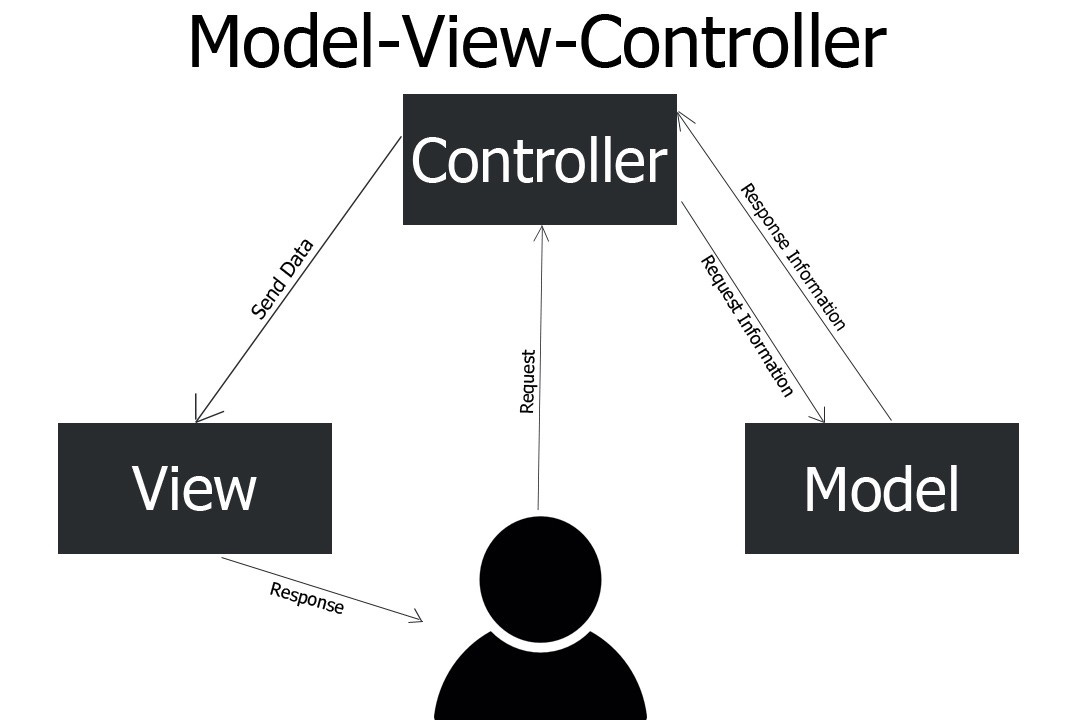
¿A que es bonito?
El problema es que este diagrama solo se cumple cuando entendemos la vista como un ente estático. Es decir, nuestros controladores procesan unas peticiones de información (por ejemplo, el acceso a una landing page), estos solicitan la información al modelo (que en última instancia podría ser una base de datos) y finalmente envían esa información a la vista que simplemente la pinta de forma bonita.
De hecho, la idea principal por la que se rige este patrón es la escalabilidad y para ello es importantísimo que los controladores se mantengan lo más concisos posibles, haciendo de intermediarios y delegando en cada capa (modelo y vista) las responsabilidades correspondientes.
Es un patrón que si entendemos la vista como un HTML que recibe una serie de “variables” con información y simplemente las estructura y representa, funciona muy bien.
Pero si entendemos la vista como una aplicación en si misma que no solo imprime información, sino que sufre alteraciones en función de un modelo, el patrón MVC se convierte en esto:
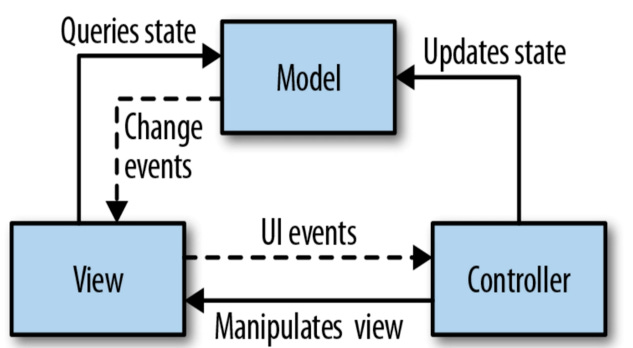
Claro. Es que, si la vista es un HTML estúpido que solo coge variables y las imprime, como hacían las aplicaciones hace 10 años, pues el MVC es un patrón perfectamente válido. Pero cuando la vista es algo vivo que ante cambios en información genera dinamismo, la interacción de las capas del patrón se ha de volver más laxa.
El controlador ya no solo habla con el modelo y envía información a la vista. Es la vista la que se bindea al modelo para obtener la información (porque si solo quiero leer la información de una estructura de datos, para que voy a pasar por el controlador) y el controlador manipula la vista cuando ante determinados cambios en el modelo de datos se necesitan cambios drásticos en la vista, por ejemplo, si hay que mostrar una modal o mover la información a otro sitio.
Así los controladores ya dejan de ser concisos y se convierten en una maraña de jQuery mutando los nodos del DOM ante cambios del modelo que impliquen cambios destructivos o de creación en la vista. Y además reciben los eventos (en aumento, a medida que las aplicaciones se vuelven más dinámicas) que actualizan el modelo en consecuencia.
En resumen, la formula perfecta para el desastre.
Este fue el esquema seguido por frameworks como BackboneJS y jQuery, y que todavía a día de hoy tenemos que mantener. Un esquema, que ya digo, funcionaba bien para el tipo de aplicaciones web que se construían hasta más o menos la primera década de los 2000. Pero que empujamos hasta el límite de sus posibilidades a medida que la vista se volvió más importante.
Comunicación bidireccional
Parte de la crecida en complejidad de las aplicaciones que seguían este patrón, se debía a que la comunicación con la información se producía por múltiples vías. Esto generaba lo que se conoce como renders no deterministas ya que al alterar la vista desde diferentes puntos y atendiendo a eventos en capas distintas, nunca podemos saber que vista va a generar que cambio.
Por ejemplo, si como hemos dicho que la vista “bindeaba” directamente la información que podía pintar sin alterarse así mismo (por ejemplo, el h1 de una página) pero además el controlador podía mutar la vista (para crear o destruir elementos) a partir de eventos de usuario, el flujo no es determinista. Es decir, en según qué casos la dirección podrá ser:
Vista → Controlador → Modelo → Vista
Vista → Controlador → Vista
Vista → Controlador → Modelo → Controlador → Vista
Controlador → Modelo → Vista (side-effects)
Controlador → Modelo → Controlador → Vista (side-effects)
Este no determinismo para un cerebro humano estándar es un cacao importante.
Así, para simplificar esto y antes de pararnos a pensar siquiera si el MVC era el patrón adecuado para el tipo de aplicaciones que se empezaban a construir, algunos frameworks como AngularJS o KnockoutJS introdujeron el concepto de comunicación bidireccional que recogía los flujos Modelo → Vista y Vista → Controlador → Modelo, pero de una forma que para el programador pareciese que solo gestionaba un flujo.
Es decir, las desarrolladoras solo tendrían que preocuparse de actualizar una pieza de información y los frameworks se encargarían (de forma transparente) de hacer la sincronización entre todos los flujos.
¿El problema de esto? que hace falta un framework con sintaxis de framework para poder conseguir el efecto de que parezca que solo hay un flujo, ya que con vanilla Javascript no podía hacerse. El otro problema es claro, falta de transparencia al arrebatar a los programadores la habilidad de saber exactamente cuando un cambió en la información va a provocar un renderizado en la vista.
Por eso AngularJS es tan fácil y complejo de usar a la vez. Fácil porque abstraen al programador, complejo porque las programadoras están tan abstraídas que no saben ni cómo ni cuándo pasan las cosas.
MVVM, MVP, y otras vainas
Una de las cosas más difíciles de arquitectura de software es saber ante qué cambios en las especificaciones hay que repensar el diseño. La respuesta normalmente suele ser “siempre”, pero a veces hay que saber priorizar y evolucionar un software sin estar constantemente cambiando el diseño.
Por eso es importante que las aplicaciones sean resilientes y que ante cambios en las specs (que vendrán sí o sí) el diseño se pueda adaptar fácilmente, pero recordando siempre que ante cambios en el cómo hacemos las aplicaciones nos planteemos como mínimo si una determinada arquitectura sigue o no siendo válida.
Esto es lo que pasó un poco con MVC, ya que las aplicaciones fueron creciendo en una dirección distinta a la planteada en ese patrón y empezaron a surgir problemas para los cuáles no estaba pensado. Por lo que al final acabamos adaptando el patrón a la aplicación en lugar de la aplicación al patrón, acabando con unas implementaciones que no solo no se beneficiaban de todas las ventajas que se clamaba tener, sino que además generaba unos problemas para los cuáles no existía solución.
Uno de esos problemas ya lo hemos visto, y era el trasladar la lógica de presentación a los controladores, rompiendo por el camino el principio de única responsabilidad, al estar estos gestionando comunicación entre modelo y vista y además definiendo el cómo íbamos a actualizar la vista en función de qué cambios en los modelos.
Esto ocurría porque la forma que había de hacer vista no era declarativa, es decir no decíamos que queríamos pintar sino cómo teníamos que pintarlo. En ese caso, accediendo a nodos de un árbol y actualizándolos directamente desde el controlador. Suena terrible y lo era.
Otro problema era la perversión del modelo. Al venir de aplicar MVC a aplicaciones donde la carga de trabajo estaba en la capa de datos, habíamos tendido a pensar en el modelo como “información a guardar en una base de datos”. Sin embargo, con la llegada de las aplicaciones front dinámicas, había aparecido un nuevo tipo de información que poco o nada tenía que ver con las bases de datos, que era el estado en el cual se encontraba la vista en un determinado momento.
A raíz de estas variaciones fueron saliendo versiones adulteradas del patrón MVC. Entre ellos el patrón Modelo/Vista/VistaModelo que le daba responsabilidad a ese estado puramente más de vista pero que acababa centralizando en una única capa toda la maraña de código que le decía a la vista como pintarse.
De forma similar, el patrón MVP que a alguna lumbreras3 se le ocurrió que todos nuestros problemas se solucionarían si en lugar de llamar al controlador "controlador", lo llamábamos Presenter porque hacía mucho tiempo que había dejado de “controlar”. La realidad es que, aunque conceptualmente tenía más sentido, en la práctica (obviamente) generaba los mismos problemas que MVC.
Realmente los usos de MVC que se fueron dando a medida que el frontend fue cobrando más y más importancia, fueron MVP.
Introducción a Flux
Flux fue creado por Facebook4 precisamente como alternativa a ese modelo bidireccional que proponía MVC y sus variantes, ya que hacía muy difícil la depuración y el rastreo de errores.
Este patrón además se sustentaba en el cómo nos estábamos empezando a acostumbrar a hacer vista en React: declarativamente. Al no tener que preocuparnos por el bajo nivel de pintar elementos en un documento HTML, pudimos caminar hacía un mundo ya por defecto más determinista, al disponer de componentes que tomaban un estado y renderizaban HTML.
Así Flux es un patrón de aplicaciones Frontend pensado para resolver los problemas que había en el Frontend y que plantea un flujo unilateral con renderizados deterministas:

Primero fíjate en la diferencia clara con MVC a la hora de acceder al modelo. Tiene sentido que la vista se alimente directamente del store porque esta es una representación del mismo, pero a diferencia de lo que ocurría con el controlador en MVC, ahora no accedemos directamente al store, sino que este es generado a través de un despachador de acciones.
Así el flujo sería:
Se genera una acción (a través de un evento del usuario por ejemplo),
El despachador toma esa acción y se la pasa al store para generar un nuevo estado,
La vista toma el nuevo estado y genera un nuevo HTML.
Es importante notar que la acción no es una llamada a una función, sino más bién un comando que describe el tipo de acción a realizar y que además puede guardar información.
Reducers
El patrón flux ha sido muy alimentado por Redux, una librería de gestión de estado que bebe directamente de lenguajes como Elm y que tiene como objetivo el acercar el patrón flux al paradigma funcional5.
Esta librería introdujo el concepto de Reducer para que a partir de acciones concretar poder generar un nuevo estado.
Así y de igual forma que cuando reducimos un Array a otro tipo de dato utilizando la función reduce, en Redux los reducers reducen un stream de acciones a un nuevo estado:
function reducer(action, state) {}El paradigma funcional está muy presente aquí al ser el reducer una función pura que, dada una acción, devuelve un nuevo estado con el resultado de aplicar esa acción.
Nosotros solo tenemos que preocuparnos de implementar esa función reductora y será (habitualmente) una librería la que se encargue de gestionar todo el flujo.
Acciones
Como bien hemos dicho antes, las acciones son objetos que representan un tipo de alteración del estado. Serían como las instrucciones o el contrato que después implementarían los reducers.
Así, por ejemplo, una acción para incrementar un valor en dos pasos, podría tener esta pinta:
const incAction = {
type: 'INC',
payload: 2,
}Como ves, la acción no sabe nada ni de la variable que incrementará ni de la forma que tiene el estado. Simplemente es un contrato que define una potencial incrementación.
Es en el reducer donde más adelante implementaremos esa interfaz:
function reducer(action, state) {
if (action.type === 'INC')
return { ...state, state.count + action.payload };
return state;
}Importante darse cuenta de que el reducer siempre devuelve un nuevo estado, por lo que, si queremos solo actualizar una parte de él, tendremos que crear un nuevo objeto con lo que había antes, más lo nuevo. En este caso estamos actualizando la propiedad ‘count’ de un supuesto estado, sumándole el payload de la acción (que, si recordamos en el ejemplo, era 2).
Es buena práctica en general usar el patrón factory siempre que hablemos de creación de objetos, ya que separan la lógica de construcción de la de inicialización de la instancia. Por eso cuando hablamos de acciones, nos solemos referir directamente a sus factorías, denominadas action creators o creadores de acciones.
Así la acción actualmente definida quedaría así con un action creator:
const inc = (step) => ({
type: 'INC',
payload: step,
});Y podríamos usarla en nuestro reducer directamente:
const initialState = {
count: 1,
};
const newState = reducer(inc(2), initialState);
console.log(newState); // { count: 3 }Como puedes ver, el reducer es una función pura que dado siempre el mismo input genera el mismo output, por lo que hacer tests unitarios aquí es supersencillo.
Dispatcher en Flux
En las aplicaciones Frontend que utilicen este patrón, solo tendremos que preocuparnos de implementar nuestros action creators y el reducer, el resto: despacho y renderización se hacen por librerías externas.
Este despachador no es más que una función que toma una acción y se la pasa al store que internamente hará uso de nuestro reducer para obtener el nuevo estado que finalmente pasará a la vista para repintarla.
En el caso de Redux, el dispatcher es gestionado por Redux y la renderización por React, pero hoy por hoy es posible utilizar este patrón directamente en React usando el hook useReducer:
function App () {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div>
<span>{state.count}</span>
<button onClick={() => dispatch(inc(2))}>Inc</button>
</div>
);
}En este ejemplo puedes ver como haciendo uso de los elementos creados anteriormente, hemos construido la aplicación usando el hook useReducer.
Como puedes ver, no tenemos que preocuparnos de nada más que no sea lanzar acciones ante eventos de usuario.
Aunque Flux fue concebido pensando en React, lo cierto es que es aplicable a casi cualquier librería de UI e incluso de no UI por su enfoque determinista.
Qué pasa con los side-effects
Todo esto está muy bien, pero nos hemos dejado fuera a un actor muy importante. Me estoy refiriendo a los side-effects. Y es que no es realista plantear ningún patrón sin hablar de ellos ya que todas las aplicaciones reales lo usan.
En una aplicación real no solo el usuario lanza acciones a través de eventos de interfaz, sino que habitualmente son procesos asíncronos pasivamente llamados por el usuario o no, los que han de producir un cambio en la vista.
Y esto puede ser, desde una petición asíncrona a un servicio de back que se ha resuelto hasta cambios enviados directamente por un servidor mediante un socket.
Así con este nuevo actor en escena, el diagrama anterior se parece más a este:

Aquí dejamos representado lo que hemos hablado, no solo la vista (a través del usuario) puede lanzar acciones, si no que otros entes pueden también lanzar acciones.
Ahora bien, para mantener el paradigma funcional que promovía Redux y por tanto mantener el código funcional separado de los side-effects, se recurrió a una técnica bastante común de este paradigma: las funciones lazy.
Thunks
Las funciones lazy (o también llamadas thunks) son funciones que representan operaciones que serán ejecutadas en un punto en el futuro o cuando los recursos necesarios estén listos para ser usados.
Esta idea suele marcar un punto de inflexión en la curva de aprendizaje de este patrón porque da por sentado que entiendes los mecanismos por los cuáles se gestionan los side-effects en lenguajes puramente funcionales.
Yo aquí no voy a dar por sentado nada y voy a contarte como se gestionan de forma funcional hasta tal nivel que podríamos incluso hablar de que no hay side-effects.

Toda la magia radica en que un side-effect no es un side-effect hasta que sucede. De tal forma que nosotros podemos representarlos y trabajar con ellos, pero no ejecutarlos hasta el último momento. Es clave que te quedes con esto, porque es importante.
Además, la programación funcional habla de funciones puras, que quiere decir que son funciones que cumplen estas dos reglas:
No tiene side-effects.
Dado el mismo input siempre produce el mismo output (auque esto realmente, es un subproducto de la primera regla).
Entonces, si yo tengo esta función:
function getName () {
console.log('This is a log');
return 'Sara';
}Claramente no es una función pura puesto que primero, tiene side-effects (ese console.log de ahí) y segundo no produce el mismo output siempre (precisamente por acceder a console que es una variable global mutable por cualquiera).
Ahora bien, que pasa si en lugar de operar directamente con getName (que hemos visto que es una función impura), operamos con esta carcasa:
function LazyGetName () {
return getName;
}Esta vez tenemos una función que, sí que devuelve lo mismo en teoría, pero getName sigue siendo una función global. Vamos a arreglar eso:
function LazyGetName () {
function getName() {
console.log('This is a log');
return 'Sara';
}
return getName;
}Ya getName es una variable local y por tanto LazyGetName no accede a variables globales, dado el mismo input siempre devuelve la misma función y no dispara side-effects.
Javascript no es un lenguaje 100% funcional y no mantiene la pureza de sus funciones. Por lo que en este caso el output será siempre una función con una referencia nueva. Para el caso nos vale puesto, que aunque la referencia cambie, el cuerpo de la función es igual.
Pues bien, ahora tenemos una función que mantiene nuestro side-effect aislado.
Siguiendo esta misma línea, vamos ahora a crear otras funciones puras que en lugar de operar con valores directamente, envuelvan todo en una función:
function toUpperCase(f) {
return () => f().toUpperCase();
}
function addLastName(f, name) {
return () => `${f()} ${name}`;
}Importante aquí que estas utilidades devuelvan nuevas funciones, porque en cuando hagamos f() la función se vuelve impura porque estaría ejecutando el console.log.
Y así podemos trabajar con getName sin llegar a ejecutarlo nunca:
const SaraUpperCase = toUpperCase(LazyGetName());
const SaraWithLastName = addLastName(SaraUpperCase, 'Perez');Hemos transformado un valor en un valor próximo por medio de encerrarlo en una función. Esto en matemáticas se conoce como Isomorfismo6.
Finalmente, en el último momento podemos ejecutar la función lazy y ejecutar todas las transformaciones y los side-effects:
SaraWithLastName()
// This is a log
// SARA Perez
Usando Thunks en Flux
Pues bien, en la arquitectura Flux usamos los thunks cuando para poder despachar una acción, necesitamos que previamente se ejecute otro proceso, normalmente asíncrono:
function logInc (step) {
return function (dispatch) {
console.log('hello');
dispatch(inc(step));
}
}Así podemos proporcionarle al thunk la información de la que disponemos y una vez que se procesen los side-effects, despachar la acción de verdad.
Si no tuviéramos thunks, tendríamos que llevar estas lógicas a las vistas o peor aún al reducer (que debería de mantenerse puro a toda costa).
Ahora para poder usarlos solo necesitamos despachar el thunk como si de una acción normal se tratase:
dispatch(logInc(2));Este código funciona sin más en Redux, pero para usarlo con useReducer tenemos que adaptar el comportamiento creando una nueva versión del mismo:
function useReducer (reducer, initialState) {
const [state, dispatch] = React.useReducer(reducer, initialState);
const customDispatch = action => {
if (typeof action === 'function') {
return Promise.resolve(action(dispatch));
}
return Promise.resolve(dispatch(action));
}
return [state, customDispatch];
}O podríamos quitar las promesas si obligamos a que la función en la que englobamos a los side-effects es siempre asíncrona (como hace Redux).
Conclusión
Hemos visto el por qué patrones como Flux han cobrado tanta importancia en los últimos años por estar construidos para solucionar problemas de Frontend concretos en lugar de adaptar enfoques tradicionales de Backend a aplicaciones dinámicas.
Además, hemos definido el patrón de Flux e introducido sus diferentes componentes dando además implementaciones concretas.
En artículos posteriores profundizaremos en el manejo de side-effects y veremos una vez más como la programación funcional tiene mucho que aportar en este aspecto.
¿Y tú, usas este patrón? ¿te gusta? ¿qué te aporta y que te quita?
Os leo en comentarios.
Nada más por hoy :).
https://en.wikipedia.org/wiki/Trygve_Reenskaug
https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
https://dle.rae.es/lumbrera
https://facebook.github.io/flux/
https://redux.js.org/introduction/getting-started
https://es.wikipedia.org/wiki/Isomorfismo
excelente explicación, aunque al final confunde un poco.