
Tipos de datos abstractos para especificar software
Definiendo e implementado ADTs para modular nuestro código


El desarrollo de software está lleno de retos y aunque solemos disponer de muchas herramientas para abordar problemas, las soluciones muchas veces no se pueden usar como nos gustaría o se requiere. Y es que creo, que a todo el mundo le sonará el ejemplo de estar varios días trabajando en algún módulo, con sus tests unitarios y con un montón de cosas guays que ni siquiera estaban contempladas en el diseño original, pero que por no haber dedicado suficiente tiempo en pensar el API y en definir los axiomas, resulta que cuando lo intentamos usar en producción, no vale para nada.
En contraposición por ejemplo a esos tipos como un Array o un Set que no importa ni siquiera el lenguaje de programación, automáticamente sabemos cómo usarlos y cómo se comportan.
En el artículo de hoy introducimos el concepto de ADT, para dar nombre a muchas de las cosas que hemos ido viendo aquí en el blog y para intentar mejorar el proceso por el cuál creamos módulos de cualquier tipo.
El software es muy complicado
Se estima que hay más de 100 millones de líneas de código en un coche de gama alta1. Imagina tener que leer y entender cada una de ellas y ya no te digo intentar encontrar un bug. Es por eso que creo que las herramientas de IA rollo ChatGPT2 van a tener mucho que aportar a la hora de explicarnos un mundo que, si bien hemos construido nosotros, ya no entendemos.
Esto que es un problema ahora, lo era aún más en la década de los 60 y 70 donde no se tenían estas herramientas de IA, patrones de diseño, linters, intellisense ni otros analizadores estáticos de código. De aquella, todo el software era un conjunto de código que hacía cosas sin estar relacionado por nada, por lo que era imposible entender cada una de las piezas de un sistema por separado, porque no había ninguna pieza que entender.
Es por eso que se empezó a trabajar en la idea de la modularidad, o lo que es lo mismo: el poder entender un software en piezas modulares sin tener que entender todo el sistema.
Hoy a esto lo conocemos bajo el principio de “locality” o cercanía de las referencias y que podemos resumir en la habilidad que tenemos de agrupar el código en módulos que lo describan, sin ambigüedades y sin tener que entender el cómo está implementado.
Por ejemplo, nosotros podemos entender lo que representa un Array y las operaciones que podemos hacer con ellos, sin tener que saber el cómo se implementó.
Esta necesidad de modular y localizar partes de un programa, fue lo que allanó el camino para que entre 1974 y 1975, Barbara Liskov3 y sus estudiantes definieran la idea de los ADTs: Abstract Data Types4.
Si eres seguidor asiduro, te sonará el nombre de Liskov puesto que fue una de las mujeres que definió el concepto de promesas.
Las contribuciones de Liskov a la abstracción de datos y a la computación distributiva han sido tales que en 2008 se le otorgó el premio Turing5. Este premio es otorgado anualmente a quienes hayan contribuido de forma trascendental al campo de las ciencias computacionales.
Especificaciones como herramienta para entender software
Un ADT o tipo de dato abstracto que define una serie de axiomas sobre el mismo. En programación, un axioma es una propiedad que asumimos cierta sin necesidad de una prueba.
Volviendo al ejemplo de los arrays, podemos ejecutar la operación push (que está definida como la forma de introducir un valor al final de una colección), sin que tengamos que comprobar que realmente se ha introducido ese valor al final. La especificación así lo define, la damos por verdadera y no tenemos que comprobarlo cada vez.
Si no conocemos los axiomas de una pieza de software, no podemos entenderla ni usarla sin necesidad de entender su implementación.
Muchos estaréis pensando en que los ADT son documentación de uso y el final último podemos entenderlo así, pero la clave está en verlos como modelos matemáticos que dan una visión de alto nivel sobre la información y operaciones que representan, pero no dan ningún detalle sobre cómo se deberían de implementar.
Como referencia, tenemos unos criterios principales que deberían de seguir los ADTs:
Formales: La especificación tiene que profundizar lo suficiente como para que el público objetivo pueda construir una implementación.
Mínimos: Las entradas y salidas y los axiomas deben de ser descritos en detalle, pero nada más. Recuerda que los ADTs no hablan en ningún caso de la implementación.
Declarativos: La forma en la que describen tiene que hablar del qué y no del cómo.
Extensibles: Deberían de poder ser extensibles por otros ADTs sin necesidad de tener que cambiar toda la especificación.
Aplicables: El lenguaje en el que se describen los ADTs debe de ser lo más agnóstico posible al lenguaje y al programa para que sean aplicables en diferentes casos de uso.
Además de esto, es lo que estamos hablando, necesitamos que toda la información descrita por un tipo de dato abstracto, sea fácil entendible por humanos, las definiciones sean claras y se describan en detalle sus axiomas (u operaciones).
Fantasy land

No me estoy refiriendo a un mundo donde vivamos todos cogidos de la mano y lleno de amor (aunque quizá ese sea mi sueño si todos usasemos la programación funcional lol), sino a una especificación de tipos abstractos muy usada por librerías de programación funcional como ramda6.
Fantasy land es un repo de Github que define una especificación sobre una serie de ADTs que bebe directamente de las ideas de la programación funcional. Por ejemplo, uno de estos ADTs es el Functor, un tipo del que hemos hablado mucho aquí en el blog.
Echemos un vistazo a lo que dice la especificación sobre el Functor:

No explica que es un Functor, ni entra en detalles sobre para que podríamos usarlo o cómo implementarlo. Lo único que habla son de los axiomas que este potencial tipo debería de tener.
En este caso, dado un tipo u, debería de haber una función fantasy-land/map que soporte identidad y composición de la forma en la que está ejemplificada ahí.
Si nos vamos ahora a la especificación concreta de la función fantasy-land/map, encontramos información sobre las entradas y las salidas, crucial para poder implementarlo:
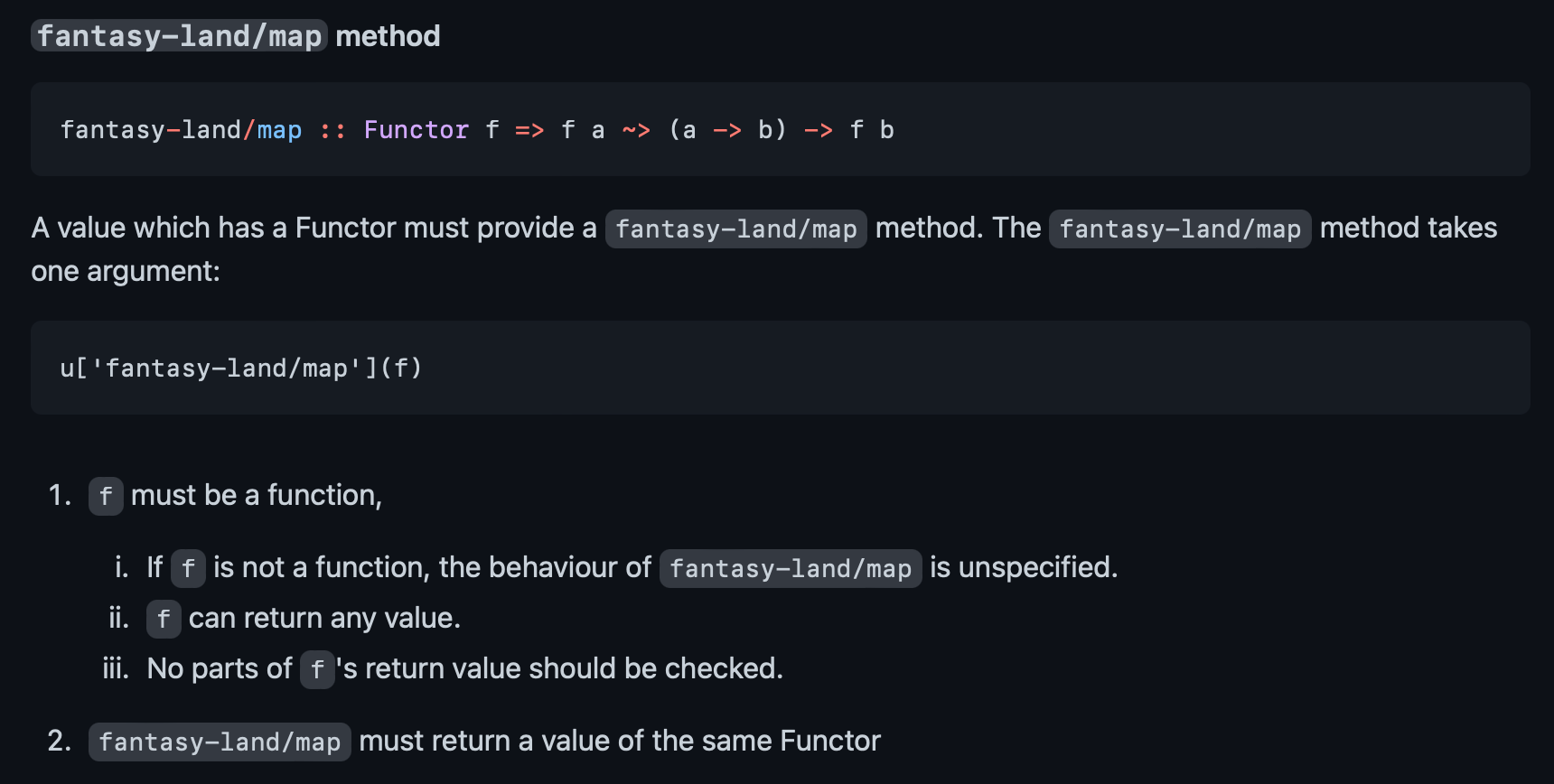
Esta especificación se basa en las anotaciones de tipos de Haskell7 para expresar las relaciones entre las entradas y salidas, así como de los tipos concretos que espera.
Así, un Functor de un valor cualquiera es un ADT con una operación map que nos permite aplicar una función sobre el valor del Functor.
La función que le pasamos a map tiene que ser del tipo Function (en caso de que no lo sea, la especificación no establece ningún comportamiento, por lo que es decisión del que lo implemente el decidir uno). Además, la función podría devolver cualquier tipo, pero el resultado de la función fantasy-land/map del Functor debería de ser del mismo tipo del Functor (para que se cumplan las reglas de identidad y composición que se han definido más arriba).
La especificación de Fantasy land define muchos más ADTs, como, por ejemplo:
Group
Semigroup
Monad
Applicative
Así como las dependencias entre ellos:

Con toda esta información abstracta podemos implementar los ADTs sobre tipos concretos y validar que todo sea correcto probando los axiomas que nos proporcional la propia especificación.
Implementando un ADT
Hemos visto más arriba como la especificación de Fantasy land recoge la visión general sobre como un potencial tipo Functor debería de comportarse. En aras de encajar todo lo que hemos comentado sobre los ADTs, vamos a proceder a implementar el Functor tal y como esa especificación lo define.
Vamos a empezar definiendo las pruebas con los axiomas que se nos proporcionan:
// test.js
import assert from 'node:assert/strict';
import Box from './index.js';
const b = Box(1);
assert.notEqual(b, undefined);
assert.equal(typeof b['fantasy-land/map'], 'function');
// identity
assert.equal(
typeof b['fantasy-land/map'](x => x)['fantasy-land/map'],
'function'
);
assert.equal(
b['fantasy-land/map'](x => x).value,
1
);
// composition
const f = x => x + 1;
const g = x => x * 2;
assert.equal(
b['fantasy-land/map'](x => f(g(x))).value,
b['fantasy-land/map'](g)['fantasy-land/map'](f).value
);Solo hemos hecho las pruebas sobre una futura estructura llamada Box, con los axiomas que están descritos en la especificación.
Ahora solo tenemos que implementar la estructura cerciorándose de que esas pruebas se cumplan:
// index.js
export default function Box(x) {
return {
'fantasy-land/map': (f) => Box(f(x)),
value: x,
}
};El código y las pruebas las he hecho usando Node.js 19
¡Y nada más!, ahora podemos usar este tipo en nuestros desarrollos y junto con otros módulos que se sustenten en esta especificación. Los usuarios de nuestra Box no tienen que conocer los detalles de cómo está implementada ni cerciorarse de que los axiomas se cumplan, simplemente seguirán la especificación definida por el ADT de Fantasy land.
Imagina ahora que todos los módulos de tus aplicaciones siguieran este esquema. No tendrías que volver a leer el código de cada módulo para poder razonar con el programa.
Es como una documentación, pero mejor, porque habitualmente las documentaciones se escriben a posteriori y a fuerza de leer la implementación, por lo que no te aseguras de que existan unos axiomas que siempre se cumplan y seamos sinceros, ¿quiénes de nosotros se leen los tests de un módulo para entenderlo? Nadie. Nos ponemos a usar console.log con los outputs. Que nos conocemos.
Conclusión
Los ADTs nos ayudan no solo a modularizar nuestro código, sino a dar determinismo y poder entender el software como cajas negras (que a veces son necesarias). Lo importante es siempre definir reglas y cerciorarnos de que siempre se cumplan. Si hoy llamo a map y me devuelve una cosa y mañana otra, nos obligará a leer el código para enterarnos de cómo va la movida y lo que queremos es precisamente no tener que leer cientos y cientos de líneas de código.
Si alguien se tiene que leer el código de algo para poder usarlo, hay muchas cosas que se han hecho mal. Si trabajas como desarrollador en el mundo de la automoción y te pide tu jefe que arregles el por qué algunos coches Seat se quedan bloqueados en un bucle de cargando y te tienes que leer las más de 100 millones de líneas para entender como funciona en aras de poder encontrar el bug y arreglarlo, nos espera un futuro oscuro.
Si, mi coche se ha quedado en un bucle de cargando en el login muchas veces y no funciona ni la radio XD.
Hoy en día tenemos la suerte de poder usar y razonar ADTs sin tener que preocuparnos ni cómo están implementados ni en que lenguaje casi. Estoy hablando de los arrays, sets, stacks, hasmaps, etc. Y todo es gracia a que están definidos y ampliamente aceptados. A nadie se le ocurriría hacer un Set que no mantenga la unicidad de sus elementos. De igual forma que no tendría sentido hacer una Box que no soporte composición de funciones.
Nada más por hoy ;)
https://cybellum.com/ja/blog/autonomous-risk-what-can-we-learn-from-the-complexity-of-vehicle-code-2/
https://openai.com/blog/chatgpt/qwe.sh/%2F../
https://es.wikipedia.org/wiki/Barbara_Liskov
https://en.wikipedia.org/wiki/Abstract_data_type
https://es.wikipedia.org/wiki/Premio_Turing
https://ramdajs.com/
https://www.haskell.org/